

芯东西(公众号:aichip001)作者 | GACS
芯东西9月6日报道,一年一度的全球AI芯片峰会(GACS 2024)今日在北京火爆开幕。现场座无虚席,云直播全网观看人数达到120万人次。

▲会场内和场外展台人潮涌动
大会由智一科技旗下芯东西联合智猩猩发起主办,以「智算纪元 共筑芯路」为主题,邀请50+位嘉宾来自AI芯片、Chiplet、RISC-V、智算集群、AI Infra等领域的嘉宾与会作干货分享。
正值国产GPGPU独角兽壁仞科技成立五周年,会上,壁仞科技宣布取得多芯混训核心技术突破,打造出异构GPU协同训练方案HGCT,业界首次能够支持3种及以上异构GPU训练同一个大模型。
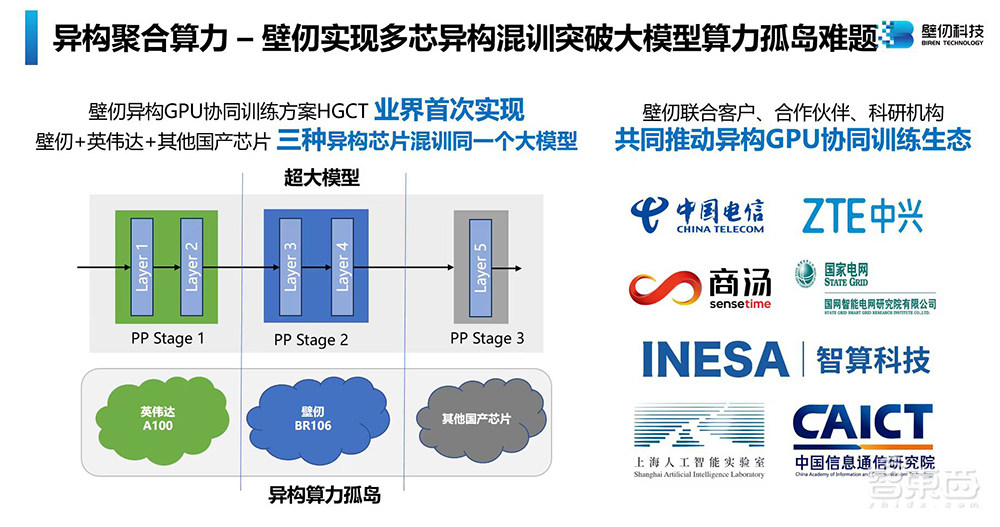
▲壁仞科技推出国产异构GPU协同训练方案HGCT
智一科技联合创始人、CEO龚伦常作为主办方发表致辞,今年是全球AI芯片峰会举办的第七年,峰会已成为国内在该领域里最有影响力的行业会议,是了解国内外AI芯片发展动态的重要窗口。

▲智一科技联合创始人、CEO龚伦常
全球AI芯片峰会为期两日,主会场包括开幕式和三大专场(AI芯片架构、数据中心AI芯片、边缘端AI芯片),分会场包括Chiplet技术论坛、智算集群技术论坛和RISC-V创新论坛。
在开幕式上,清华大学教授、集成电路学院副院长尹首一以《高算力芯片发展路径探讨:从计算架构到集成架构》为题进行主题报告,系统性复盘了高算力芯片存在的技术挑战,并全面分析五条创新技术路径:数据流芯片、存算一体芯片、可重构芯片、三维集成芯片、晶圆级芯片。
今日有21位来自顶尖高校及科研院所、AI芯片企业的专家、创业者及高管进行分享。其中,高端对话环节邀请了三家AI芯片创企代表激情交辩,分别是国产大算力芯片独角兽壁仞科技、端侧与边缘侧AI芯片独角兽爱芯元智,还有一家仅创立半年的年轻AI芯片创企凌川科技。他们集中探讨了AI芯片产业现状、最新实践与进阶方向。
一、破解大模型算力供需挑战,架构创新突围性能瓶颈
清华大学教授、集成电路学院副院长尹首一解读了大模型时代算力供需间的困难:芯片工艺面临Scaling-down极限,致使工艺红利带来的算力提升难以为继;系统面临Scaling-out瓶颈,通信带宽不足导致系统性能损失。
破解这两大难题的机会在于算力芯片计算架构和集成架构的联合创新:计算架构创新使每个晶体管都被充分利用、发挥更强算力;集成架构创新使芯片规模能够突破极限。
当前高算力芯片发展有五条新技术路径:数据流芯片、可重构芯片、存算一体芯片、三维集成芯片、晶圆级芯片。这些路径都不完全依赖于最先进的制造工艺,有助于为国内芯片产业开辟算力提升新空间。

▲清华大学教授、集成电路学院副院长尹首一
AMD在端到端的AI基础设施领域打造了全面的产品线,覆盖从数据中心服务器、AI PC到智能嵌入式和边缘设备,并提供领先的AI开源软件及开放的生态系统。AMD基于先进ZEN4架构设计的CPU处理器平台、基于CDNA3架构面向AI推理&训练的MI系列加速器,已被微软等巨头采用。
据AMD人工智能事业部高级总监王宏强分享,AMD还在推动数据中心高性能网络基础设施(UALink,Ultra Ethernet),这对AI网络结构需要支持快速切换和极低延迟、扩展AI数据中心性能至关重要。
AMD即将发布下一代高性能AI PC,其基于第二代XDNA架构的Ryzen AI NPU,可提供50TOPS算力,将能效比提高至通用架构的35倍。在AI PC对隐私、安全和数据自主性的推动下,重要的AI工作负载开始部署在PC上。作为全球领先的AI基础设施提供商之一,AMD愿意携手广大客户与开发者共建变革性未来。

▲AMD人工智能事业部高级总监王宏强
自2015年以来,高通一直在根据AI应用用例的变化,不断革新NPU硬件设计。以第三代骁龙8为代表,高通AI引擎采用集成CPU、GPU、NPU等多种处理器的异构计算架构。其中,高通Hexagon NPU通过大片上内存、加速器专用电源、微架构升级等设计来优化性能和能效。AI的用例丰富,算力要求不一,因此异构计算和处理器集成的需求会长期存在,这也将带来峰值性能、能效、成本等方面的一系列提升。
高通的产品线覆盖手机、PC、XR、汽车、IoT等丰富的边缘侧应用场景,能够支持开发者在不同产品形态中利用高通的AI软硬件解决方案进行算法加速,为消费者带来丰富的终端侧AI体验和用例。最后,高通AI产品技术中国区负责人万卫星还预告,搭载最新的高通Oryon CPU的下一代骁龙移动平台,即将在今年10月21-23日举行的骁龙峰会上发布。

▲高通AI产品技术中国区负责人万卫星
苹芯科技联合创始人兼CEO杨越拆解了存算一体技术的进阶过程。产业界主流芯片的出现和成长与当下计算需求的特点紧密相关,2015年前后,计算体系结构中的计算瓶颈从处理器端向存储端迁移,尤其是神经网络的出现,加快了AI芯片计算效率的提升节奏,存算技术因此受到关注。
杨越认为,在大模型时代,存算一体技术的机会是能够在有数据存储的地方都加入计算。随着软件不断发展,基于存算的端侧芯片今年已经逐步成熟。未来,在云端解决数据带宽瓶颈,或将成为存算芯片下一个杀手级应用。

▲苹芯科技联合创始人兼CEO杨越
北极雄芯CTO谭展宏谈道,在高性能计算领域,服务器设计有两种不同的范式:标准服务器形态和定制服务器架构。在标准服务器形态下,北极雄芯关注于在标准约束的面积下,通过合适的芯粒拆分与封装方案,实现更高的性价比;在非标准服务器形态下,提供了晶圆级集成的机会,关注于芯片与系统设计一体化,对服务器与芯片进行协同设计,旨在达到“服务器即芯片”的目标。
特别地,谭展宏强调了不同芯片的设计有不同的带宽需求,例如在7nm以上工艺下,结合部署通信优化,往往不需要很高的互连带宽密度,因此先进封装并不是必需的,基于2D的封装即可满足性能需求并实现高性价比方案。北极雄芯基于《芯粒互联接口标准》的PB-Link IP,正式实现了低封装成本的互连实现,目前已开始对外授权。

▲北极雄芯CTO谭展宏
二、高端对话:国产AI芯片造血能力增强,最年轻创企产品已落地快手
智一科技联合创始人、总编辑张国仁,与壁仞科技副总裁兼AI软件首席架构师丁云帆,凌川科技联合创始人、副总裁刘理,爱芯元智联合创始人、副总裁刘建伟,展开了一场以“国产AI芯片落地的共识、共创与共赢”为主题的圆桌对话。

张国仁在圆桌对话开始时称,由智东西、芯东西、智猩猩发起举办六届的AI芯片峰会,是国内该领域持续时间最长的专业会议,这几年见证了AI芯片和大模型的蓬勃发展,也见证了一批国内造芯“新势力”的崛起。

▲智一科技联合创始人、总编辑张国仁
丁云帆谈道,大算力芯片是技术密集、人才密集、资金密集的行业。作为市场中已公开融资规模最大的芯片独角兽,壁仞科技拥有顶级人才,第一代产品已量产落地,多个国产GPU千卡集群已经落地,能独立造血。但国产芯片行业整体情况仍然不易,生态方面和国外仍有差距。
很多国产AI芯片已经开始落地于数据中心、智算中心。在丁云帆看来,英伟达面向国内的产品性价比并不高,国产芯片只要能做出性能、做出性价比,就会有市场。目前国内芯片产业落地消息越来越多、造血能力增强,与英伟达之间的差距会逐渐缩小。

▲壁仞科技副总裁兼AI软件首席架构师丁云帆
刘建伟认为,低成本是很重要的部分,企业最终还是要算账,企业对基础设施的投资一定要赚回来。刘理相信后期在具身智能、智能视频等细分赛道,更多企业的进入,将带来比通用产品更高的价值,会压缩英伟达的营收和利润。
凌川科技是最年轻的国内AI芯片创企之一,今年3月刚成立,已完成一轮融资,目前在售的智能视频处理芯片已落地快手,占快手视频处理领域用量的99%,大算力推理芯片预计明年初流片。
在刘理看来,距离AI芯片市场窗口关闭还很远,面对巨头在资源、资金、生态上的优势,创企需要在垂直、细分领域发力。凌川科技将智能视频处理、AI推理算力结合,目标是将其每Token推理成本降到英伟达H800的10%。

▲凌川科技联合创始人、副总裁刘理
面向端侧、边缘侧的爱芯元智,市占率均取得了瞩目的成绩。刘建伟认为这两个领域实现商业闭环的速度会更快。他补充说,做AI芯片最终一定会赚钱,但实际盈利的时间表会受到AI部署成本等因素的影响,企业应尽快实现自我造血和闭环。未来,爱芯元智将在端侧和边缘侧大模型落地场景进行探索。
爱芯元智在汽车领域的产品出货量十分可观,刘建伟谈道,这是因为智慧城市和汽车的底层芯片技术类似,爱芯元智在智慧城市上积累了成熟技术再进入智能驾驶可以较快实现量产。同时,汽车领域价格战将推动产业分工是机遇期。

▲爱芯元智联合创始人、副总裁刘建伟
对于国产AI芯片如何快速找到生态位,刘建伟以爱芯元智的深耕场景为例,智慧城市基本没有国外公司,在智能驾驶领域英伟达开拓0到1阶段,1到100更关注成本的阶段就是国内企业的机会。丁云帆提到四个要素:稳定可靠的供应保障、性价比、针对客户需求提供高效支持服务、高效易用。刘理认为应该在垂直领域深耕,做出比通用芯片更高效、优化的解决方案。
展望未来,刘建伟预测未来4-5年,端侧和云侧都将出现很大的发展机遇,产业界落地成本降低后,数据可以实现更大的价值。刘理认为随着AI应用迎来爆发期,云侧将产生大量推理需求。丁云帆谈到国内的高端算力仍然稀缺,但产业链的协同可以实现稳健的发展。
三、智算中心建设潮起:壁仞GPU新突破,国产TPU拼落地,Chiplet赢麻了
在下午举行的数据中心AI芯片专场,Habana中国区负责人于明扬谈道,近三年有大约50+政府主导的智算中心陆续建成、60+在规划和建设中,智算中心建设逐渐从一线城市向二三线城市下沉,从政府主导逐渐转向企业主导,对成本压缩、投资回报周期的要求也逐渐提升。
据他观察,当前大模型开发日趋成熟,推理需求持续增长,头部CSP自研推理芯片的增速将提高,未来推理侧可能培育出多家异构芯片企业。
国外大模型训练需求仍将旺盛,国内模型训练对算力的需求基本饱和,主要来自微调业务。要支撑未来AI发展,Chiplet、高速大容量内存、私有/通用高速互联技术的融合将起关键作用。

▲Habana中国区负责人于明扬
为了打破大模型异构算力孤岛难题,壁仞科技副总裁兼AI软件首席架构师丁云帆宣布推出壁仞自主原创的异构GPU协同训练方案HGCT。这是业界首次实现支持3种及以上异构GPU协同训练同一个大模型,即支持用「英伟达+壁仞+其他品牌GPU」混训,通信效率大于98%,端到端训练效率达到90~95%。
壁仞正在联合客户、合作伙伴等共同推动异构GPU协同训练生态,包括中国电信、中兴通讯、商汤科技、国网智研院、上海智能算力科技有限公司、上海人工智能实验室、中国信通院等。
其产品已在多个千卡GPU集群开始商用落地。壁仞研发了软硬一体、全栈优化、异构协同、开源开放的大模型整体解决方案。壁仞首次实现大模型3D并行任务自动弹性扩缩容,保持集群利用率近100%;已实现千卡集群千亿参数模型10分钟自动恢复、4天无故障、15天不中断的效果。

▲壁仞科技副总裁兼AI软件首席架构师丁云帆
中昊芯英联合创始人、CTO郑瀚寻谈道,如今的AI大模型远超计算历史任一时刻的计算复杂度和算力需求量,需要更擅长AI计算的专用芯片。相较于GPU最初主要设计用于实时渲染和图像处理,TPU的设计则主要用于机器学习、深度学习模型和神经网络计算,针对张量运算进行了高度优化,单个的脉动阵列架构吞吐量和处理效率相较GPU有了更大提升。
中昊芯英自研的“刹那”芯片是中国首枚已量产的高性能TPU架构AI芯片,综合测算算力性能、成本、能耗后,单位算力成本仅为海外领先GPU的50%。郑瀚寻认为,大模型发展后期,千卡、万卡集群的最佳费效比将至关重要,刹那芯片多达1024片芯片间的直接高速互联,在构建大规模计算集群时的系统集群性性能可远超传统GPU数倍。

▲中昊芯英联合创始人、CTO郑瀚寻
据浪潮信息开放加速计算产品负责人Stephen Feng分享,随着大模型参数规模增加,生成式AI的发展面临四大挑战:集群扩展性不足、芯片功耗高、集群部署难、系统可靠性低四大挑战。浪潮信息始终坚持以应用为导向,以系统为核心,通过开元开放的系统激发生成式 AI 创新活力。
在硬件开放方面,通过建立OAM(开放加速模块)规范,加速先进算力的上线部署,支撑大模型及AI应用的迭代加速。在软件开放方面,通过大模型开发平台“元脑企智”EPAI ,为企业打造全流程应用开发支撑平台,通过端到端的解决方案,解决基础大模型落地到领域存在的幻觉问题,解决应用开发流程复杂、门槛高,多元多模适配难、成本高等落地难题,加速企业大模型应用创新与落地。

▲浪潮信息开放加速计算产品负责人Stephen Feng
清程极智成立于2023年,聚焦AI Infra赛道,团队孵化于清华大学计算机系,在智能算力优化方面,已经积累了十几年的经验。
清程极智联合创始人师天麾分享道,国产高性能算力系统正面临着故障恢复难、性能亚健康等方面的挑战,需要10大核心基础软件系统配合,清程极智已在其中过半数领域拥有自研产品。
目前,清程极智已掌握了从底层编译器到上层并行计算系统的全栈技术积累,实现大模型行业生态的全栈式覆盖,完成多个在国产芯片的高吞吐量推理优化和主流大模型的快速移植和优化,计算效果提升明显。其中,面向超大规模国产算力集群研制的大模型训练系统“八卦炉”,可扩展到全机10万台服务器规模,用于训练174万亿参数量的模型。

▲清程极智联合创始人师天麾
芯和半导体技术市场总监黄晓波谈道,算力需求过去20年增长6万倍,未来10年可能达10万倍,存储、互联带宽成为主要发展瓶颈。Chiplet集成系统成为后摩尔时代先进工艺制程限制和高性能算力提升突破的重要方向,已经广泛应用于AI大算力芯片和AI算力集群网络交换芯片。
对此,芯和半导体为Chiplet集成系统的设计开发提供了一站式多物理场仿真EDA平台。该平台支持主流工艺设计互连结构参数化建模,求解仿真能力比其他平台快10倍,内存仅占1/20,并内置HBM/UCIe协议分析以提升仿真效率,获国内外多家头部AI算力芯片设计厂商使用,帮助大算力Chiplet集成系统产品的加速落地。

▲芯和半导体技术市场总监黄晓波
在大模型训练过程中,网络基础设施的开销占比达到30%,凸显了网络性能的重要性。据奇异摩尔联合创始人、产品及解决方案副总裁祝俊东分享,网络已成为智算性能瓶颈,构建AI网络需要三网融合,即集群网间互连、机柜内互连,芯片内的互联。
大智算集群需要高性能互连,Modernize RDMA与Chiplet成为关键技术。为了优化RDMA,奇异摩尔的NDSA网络加速芯粒系列基于可编程众核流式架构,通过高性能的数据引擎,实现高性能数据流及灵活数据加速。奇异摩尔首创的GPU Link Chiplet “NDSA-G2G”,基于以太基础设施 ,通过高性能数据引擎和D2D接口技术,可实现Scale-Up网络TB级高带宽,性能媲美全球互连技术的标杆。

▲奇异摩尔联合创始人、产品及解决方案副总裁祝俊东
Alphawave是一家针对HPC、AI和高速网络应用提供IP、Chiplet和ASIC设计解决方案的企业。其亚太地区高级业务总监郭大玮分享说,针对数据在传输过程中面临的问题,Alphawave IP产品的误码率比竞品低2个数量级,还可辅助进行集成和验证,并与Arm生态深度融合。他们还能为客户的SoC提供全生命周期的支持。
Chiplet方面,Alphawave帮助客户缩短周期,降低成本,提升了良率和迭代速度,目前已做出行业内第一款多协议IO连接Chiplet,今年已经流片。定制芯片方面,Alphawave主要专注于7nm以下的工艺,可根据客户需求完成从规格到流片的全流程,目前已实现超375次成功流片,DPPM小于25。
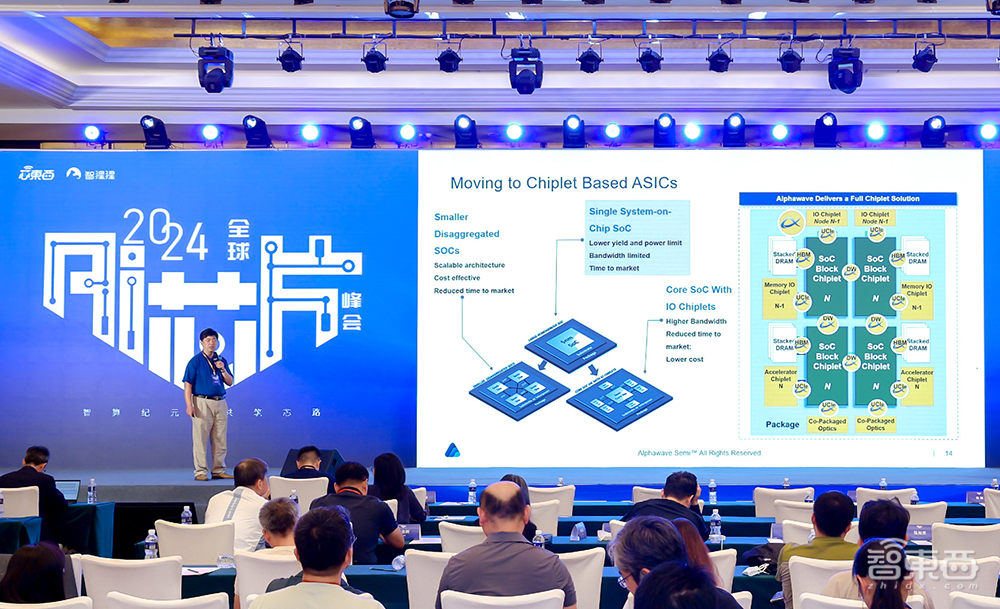
▲Alphawave亚太地区高级业务总监郭大玮
结语:下游智能化风起云涌,AI芯片迎历史机遇
在迈向通用人工智能终极议题的道路上,AI算法的形态不断变化,AI芯片也与之相随。当古老的沙砾邂逅未来的机器智能,技术与工程智慧交融碰撞,一颗颗凝集了精微设计的AI芯片走进计算集群,步入千家万户,托载起硅基生命的进化。
从智算中心、智能驾驶到AI PC、AI手机、新型AI硬件,下游智能化风潮为锚定不同场景的AI芯片都带来了新一波历史机遇。快速发展的生成式AI算法及应用不断解锁新的算力挑战。技术创新和市场需求正双重推动AI芯片市场规模扩大,并推动AI芯片的竞争格局趋于多元。
9月7日,2024全球AI芯片峰会将继续密集输送干货:主会场将举行AI芯片架构创新专场、边缘/端侧AI芯片专场,公布「2024中国智算集群解决方案企业TOP 20」、「2024中国AI芯片新锐企业TOP 10」两大榜单;分会场将举行智算集群技术论坛、中国RISC-V计算芯片创新论坛。
